How It Works
Four phases. One defensible outcome.
Nquiry isn't a chat window where you paste evidence and hope for the best. It's a structured workflow built on the same methodology used by oversight agencies, internal auditors, and compliance professionals.

Planning
Define your scope, structure your inquiry, and set up the foundation before collecting a single document.
- Write a focus statement that keeps your inquiry on track
- Define topics to organize related issues
- Draft specific questions the evidence needs to answer
- Upload background and framework documents
Collection
Gather evidence systematically. Every document, interview transcript, and dataset gets cataloged with metadata and linked to questions.
- Drag-and-drop upload for PDFs, Word docs, spreadsheets, images, and text
- Seven evidence types: Document, Interview, Website, Observation, Dataset, Note, Standard
- Link evidence to specific questions
- Text is automatically extracted and indexed for search
Analysis
The AI searches your entire evidence collection for each question, applies a professional evidence evaluation framework, and drafts findings with citations.
- Five distinct analysis types for different investigative needs
- Evidence evaluation grounded in professional oversight standards
- Automated quality checks on every analysis
- Structured investigator review before anything reaches your report
Reporting
Generate professional reports where every finding traces back to supporting evidence. Edit, refine, and export.
- Section-by-section generation: Executive Summary through Recommendations
- Every finding includes inline citations to source evidence
- Export to Word or PDF
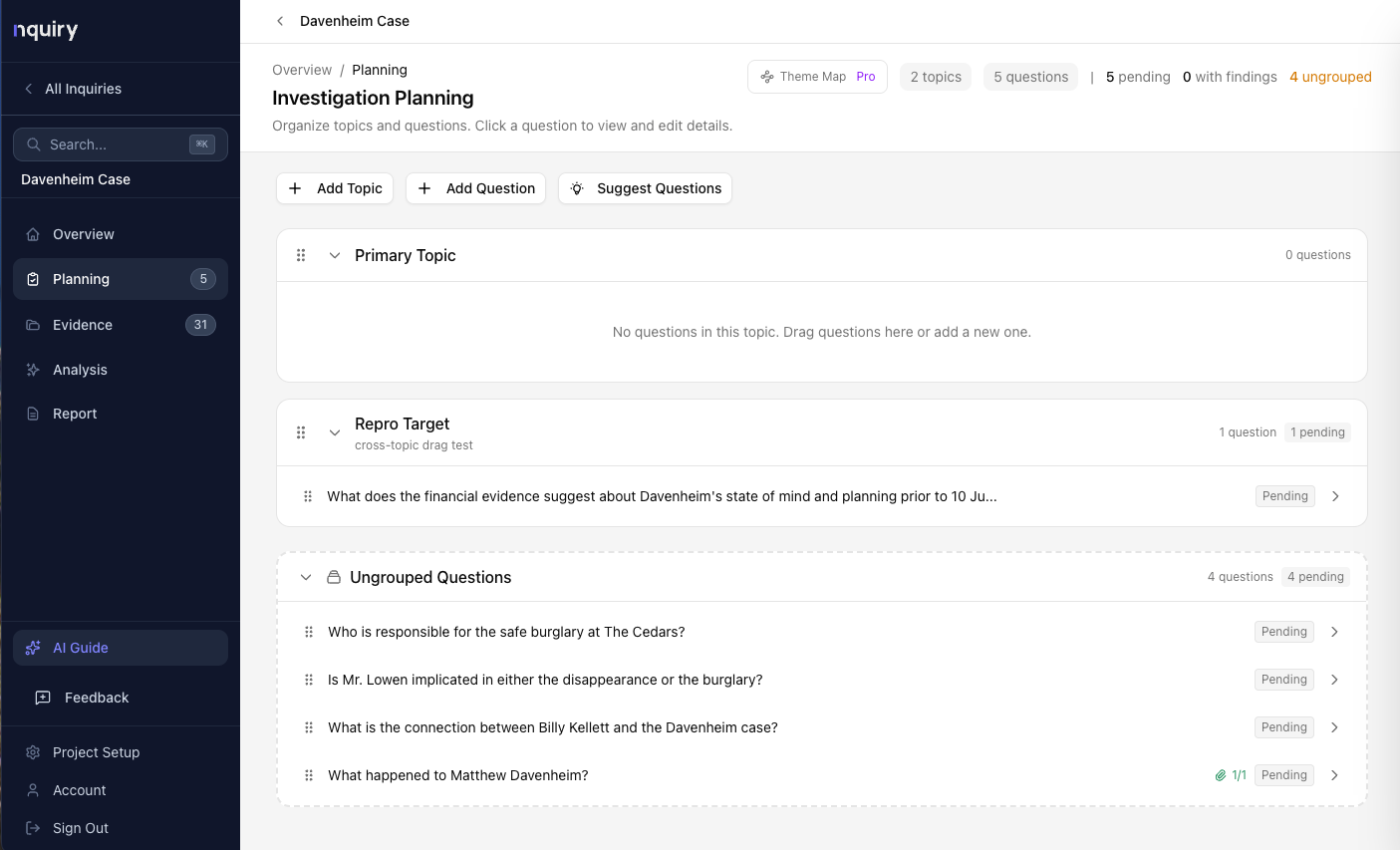
Planning
Topics and questions structure the inquiry.
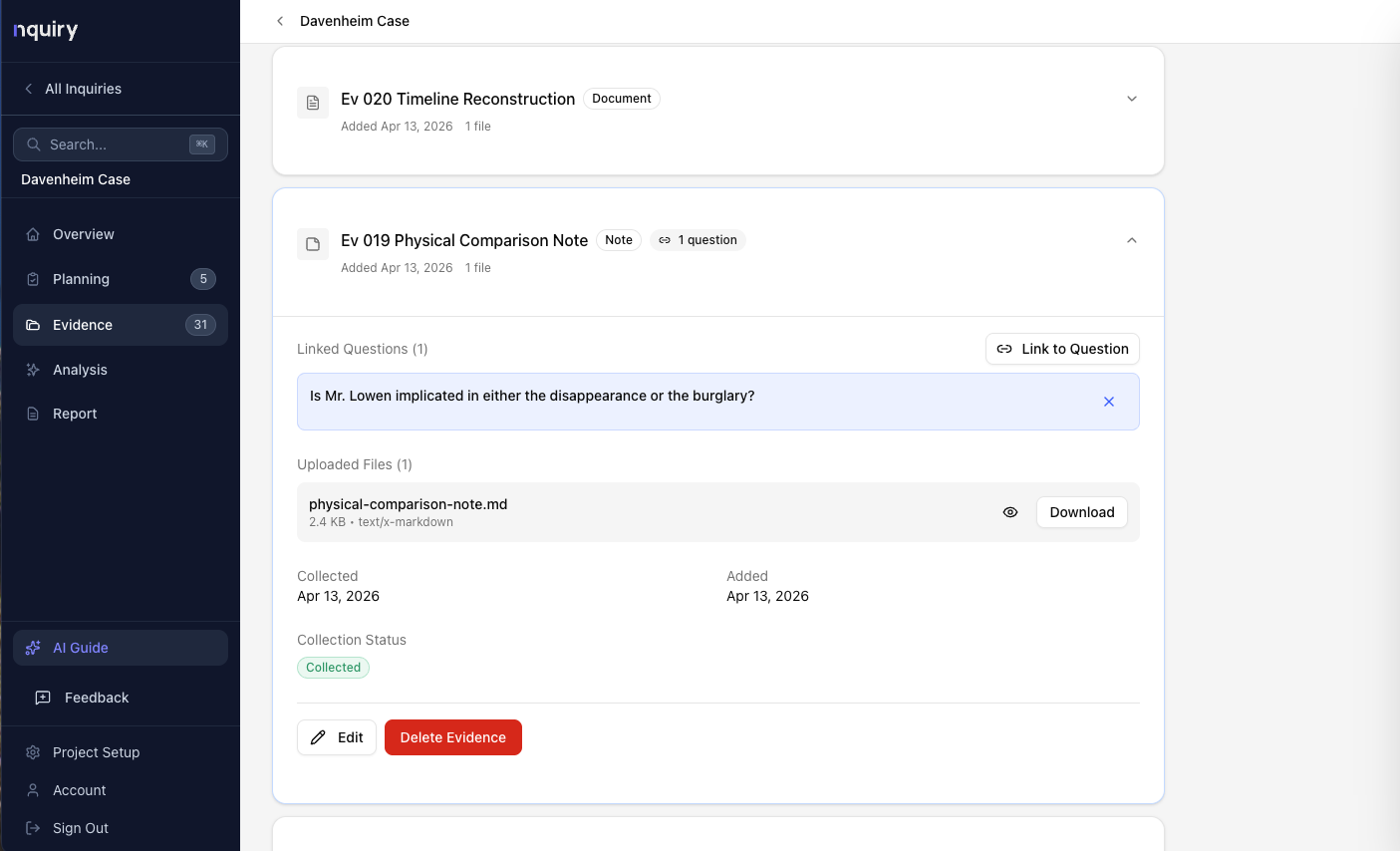
Collection
Every document cataloged and linked to questions.
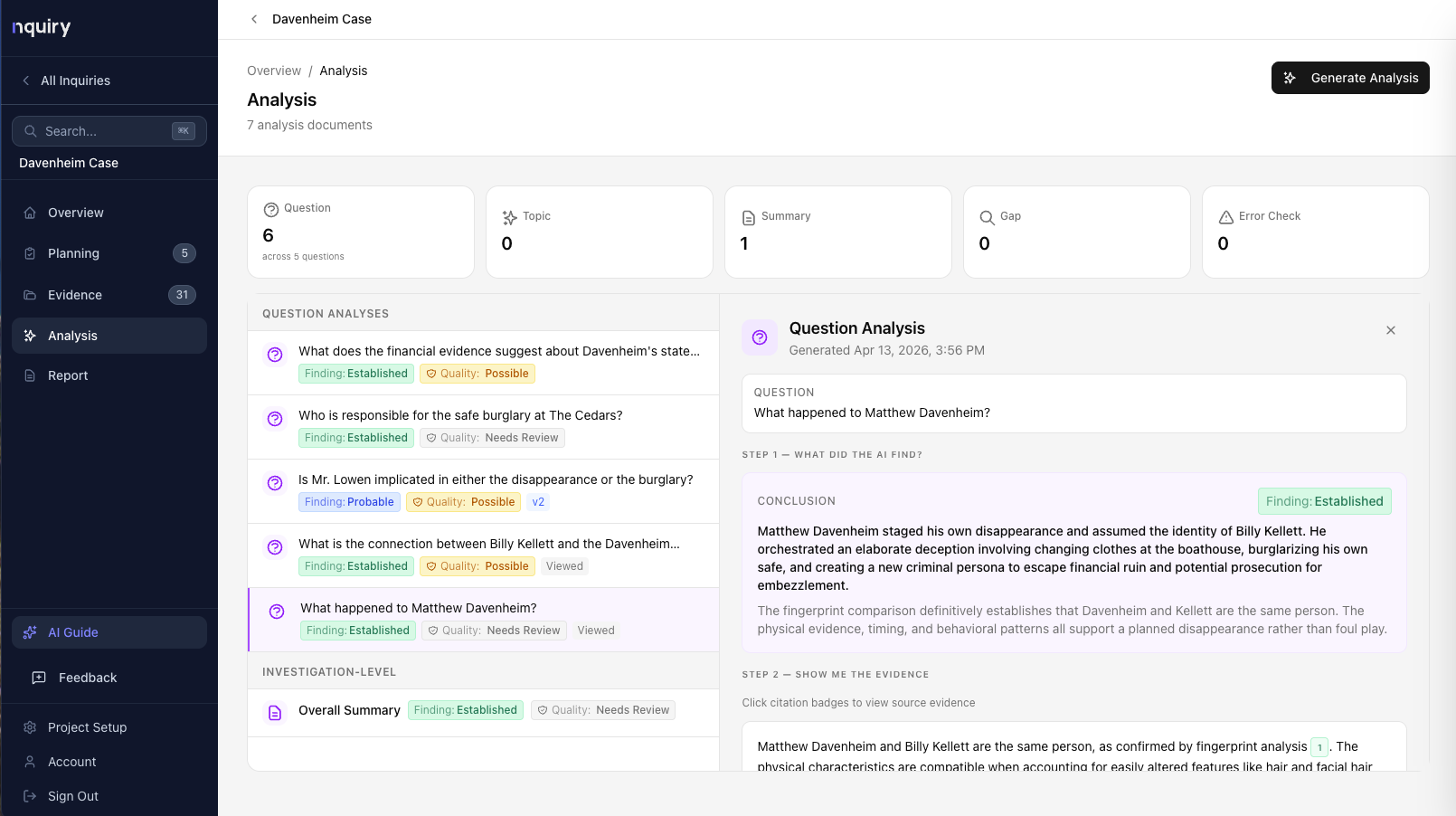
Analysis
AI drafts findings with citations — you make the calls.
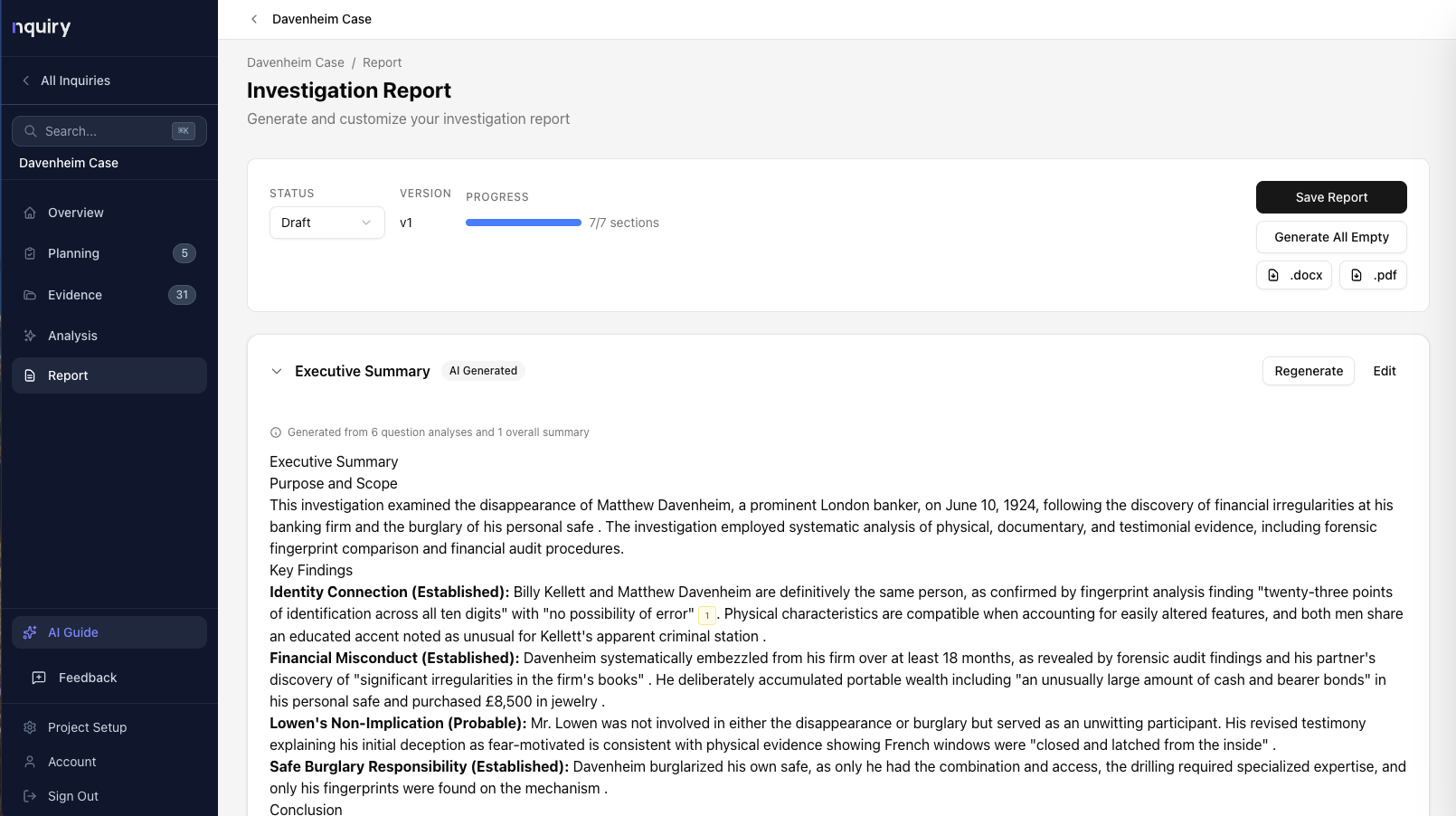
Reporting
Export-ready reports where every finding traces to evidence.
Analysis Types
Not one analysis. Five.
Each built for a different investigative need. Every type applies the same evidence evaluation framework and produces structured, citation-backed output.
Question Analysis
The workhorseEvaluates evidence against a specific investigation question. The AI searches for relevant evidence, assesses its relevance and limitations, weighs conflicting sources, and produces a finding with a confidence level and full citations.
You get: A direct answer with confidence level, the evidence that supports it, alternative explanations considered, evidence gaps identified, and recommended follow-up.
Topic Analysis
The synthesizerWhen you have multiple questions under one topic, this analysis looks across all of them to find common themes, patterns, and cross-cutting gaps.
You get: A synthesis of findings across related questions, common patterns identified, cross-cutting evidence gaps, and topic-level conclusions.
Gap Analysis
The safety netSystematically identifies where your evidence is thin, what questions lack sufficient support, and what types of evidence would strengthen your findings.
You get: Questions with insufficient evidence flagged, specific evidence types recommended, priority gaps ranked, and a roadmap for additional collection.
Overall Summary
The executive briefA high-level synthesis of the entire investigation for leadership, stakeholders, or report introductions.
You get: Key findings across all topics, overall evidence assessment, conclusions, and a clear picture of the investigation’s current state.
Error Check
The self-auditLooks across all existing analyses for internal consistency — do your findings contradict each other? Does evidence cited in one analysis conflict with another?
You get: Cross-analysis consistency review, flagged contradictions, and areas where conclusions may need reconciliation.
Professional Standards
Evidence evaluation grounded in professional oversight standards.
Nquiry's evaluation framework draws on CIGIE Quality Standards, GAO Yellow Book, IIA Standards, ACFE guidance, PCAOB, Federal Rules of Evidence, INTOSAI, and ISO 19011.
What the AI assesses
For each piece of evidence, the AI determines whether it's relevant to the question at hand and whether it has material limitations — concerns about source credibility, provenance, timeliness, internal consistency, or factual basis.
When limitations exist, the AI describes them specifically so you can weigh them in context.
How it informs your findings
Evidence assessments feed directly into the confidence level of each finding. Strong, limitation-free evidence from multiple sources pushes toward “Established.” Evidence with material concerns is still considered but weighted accordingly.
The result: every finding comes with a documented reasoning chain you can verify and defend.
The evaluation framework is informed by quality dimensions including relevance, reliability, sufficiency, validity, competence, completeness, timeliness, objectivity, authenticity, and consistency. These principles shape how the AI reasons about your evidence — not as a checklist, but as the professional lens through which every assessment is made.
Transparency
Every finding tells you how confident you should be.
A defined taxonomy based on the quality, quantity, and convergence of evidence.
Established
Strong, sufficient, convergent evidence. Multiple independent sources agree. The conclusion would be accepted by a reasonable, objective evaluator.
Probable
Good evidence with minor gaps. More likely than not, but some uncertainty remains.
Possible
Some evidence supports the conclusion, but significant gaps, conflicts, or weaknesses exist.
Insufficient
Evidence is too weak, conflicting, or incomplete to support any conclusion. More evidence is needed.
There's also Contradicted — when available evidence actually weighs against the proposed conclusion. That's not a failure. That's the system working.
Human in the Loop
AI drafts. You decide. Every single time.
Every analysis goes through a structured review flow before it can contribute to your report.
Review the analysis
Read what the AI found — the conclusion, the evidence it considered, and the confidence level.
Check the citations
Before you can agree or disagree, you must open at least one cited evidence item and verify it yourself. This is built into the interface.
Record your judgment
Agree — the analysis is sound. Disagree — something’s wrong, and you record why. Unsure — you need more before you can decide.
Direct and iterate
Provide investigator direction to focus the AI. “Focus on timeline inconsistencies.” “Evaluate against Section 3.2.” The AI incorporates your guidance without overriding the evaluation framework.
Every action — agree, disagree, regenerate, edit — is timestamped and logged. When someone asks “who reviewed this finding and when?” you have an answer.
Quality Assurance
Three independent checks on every analysis.
These aren't the same AI process that wrote the analysis. They're independent evaluations that catch problems the generating model might miss.
Faithfulness
A separate AI process examines every factual claim and checks whether it’s supported by the retrieved evidence.
95%+ means nearly all claims verified. Below 85% is flagged for attention.
Coverage
Breaks the question into constituent elements and verifies the analysis addresses each one. Gaps are identified explicitly.
Ensures the analysis actually answers what was asked.
Retrieval Quality
Every retrieved passage comes with a relevance score. The system tracks high vs. low relevance and flags weak evidence bases.
Tells you how strong the evidence foundation is.
Evidence Evaluation Pipeline
Three search stages. The right evidence surfaces every time.
When you run analysis, Nquiry doesn't rely on a single search method. It runs a three-stage evidence evaluation pipeline that combines precision, conceptual understanding, and AI judgment.
Stage 1: Keyword Search
Scans all evidence for exact word matches. Catches case numbers, policy codes, names, dates, and identifiers that must be matched precisely.
Stage 2: Semantic Search
Converts questions and evidence into meaning-based vectors, finding conceptually similar passages even when the words are completely different.
Stage 3: AI Reranking
A separate AI model evaluates every result from both searches in context, promoting genuinely relevant evidence and filtering out false positives.
For every analysis, expand the “Evidence Considered” panel to see exactly which passages the pipeline found, how they were discovered, their relevance scores, and whether they were included or excluded. Full transparency into what the AI saw when it wrote its findings.
AI that assists, not replaces.
Built-in self-audit catches potential errors and unsupported claims. You review every finding before it goes in the report. Your judgment, your conclusions—Nquiry just helps you get there faster.
The AI Guide panel sits beside your work, ready to help with navigation, methodology, and project status — without ever leaving the page.
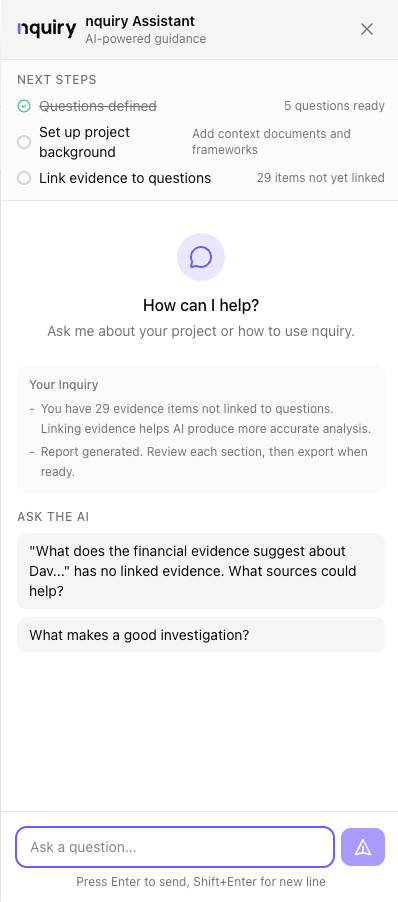
The AI Guide — Your In-App Partner
A context-aware assistant available from any page. It knows where you are in your investigation, what phase you're in, and what features are available.
- Navigation help — “Where do I upload evidence?” “How do I generate a report?”
- Methodology guidance — “What makes a good investigation question?”
- Project awareness — “Which questions don't have evidence yet?”