AI Quality Assurance
AI that checks its own work — then lets you check it too.
We validate AI quality at multiple layers, using independent checks, statistical methods, and your professional judgment as the final authority.
Multi-Layer Validation
Five layers between the AI and your report.
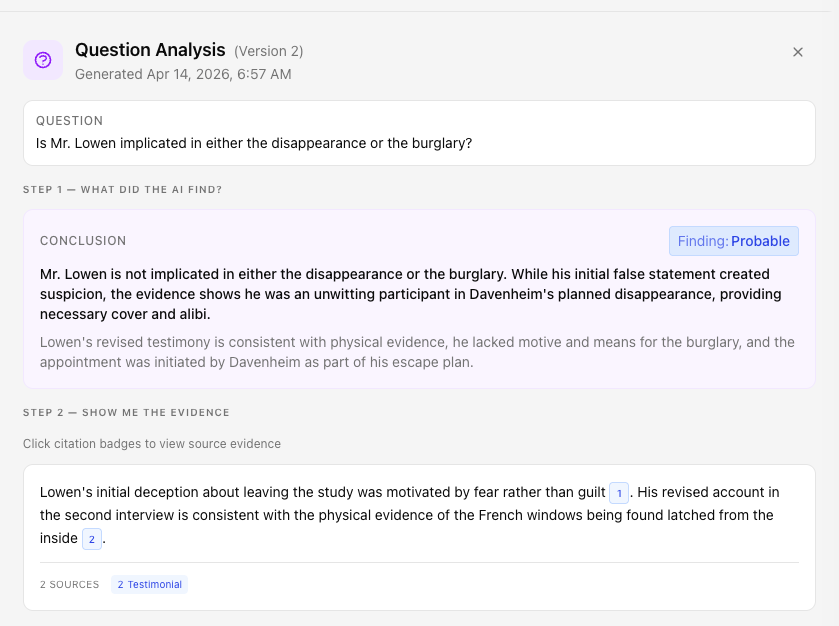
The Evidence Evaluation Framework
Before the AI writes a single word of analysis, it’s operating under a structured framework synthesized from CIGIE, GAO, IIA, ACFE, and other professional standards. Evidence quality principles — including relevance, reliability, sufficiency, and validity — shape how every piece of evidence is assessed.
This framework wasn’t generated by AI. It was designed by an oversight professional with 25+ years of investigation experience.
Automated Quality Checks
After every analysis, three independent checks run automatically: faithfulness verification (are claims supported by evidence?), coverage verification (does it address all parts of the question?), and retrieval quality assessment (how relevant was the evidence found?).
These aren’t the same process that generated the analysis. They’re independent evaluations.
Structured Investigator Review
No analysis reaches your report without passing through a structured review flow. The system requires you to expand the analysis, check at least one citation against the source evidence, and record your professional judgment.
Every action is timestamped. Every judgment is logged. This isn’t optional.
Quality Confidence Scoring
All automated checks feed into a single Quality Confidence level: Established, Probable, Possible, or Insufficient. Faithfulness and coverage scores drive the primary assessment. The logic is documented, not hidden.
Retrieval quality can lower confidence by one level but can’t drag a well-supported analysis to Insufficient on its own.
Prompt Lifecycle Management
The instructions that guide the AI go through a rigorous development lifecycle. New prompts are tested against standardized fixtures. Changes are compared against baselines.
Software engineering discipline applied to AI instructions. Prompts are tested, measured, versioned, and maintained.
Rigorous Testing
We don't just test with one model. We measure agreement across many.
Nquiry's prompts and evaluation criteria are validated using Conkurrence — a statistical validation tool we built specifically for this purpose.
How it works
We give the same evidence to multiple independent AI models and measure whether they reach the same conclusions — without telling any model what the “right” answer is. When independent models consistently agree on how to evaluate evidence, that's a strong signal the evaluation framework is measuring something real.
We use established statistical methods (Fleiss' Kappa for inter-rater agreement, Kendall's W for ranking consistency) to measure this, and every prompt must meet our agreement thresholds before it reaches production.
This isn't just internal QA. It's the same class of statistical validation used in clinical research and social science to determine whether measurement instruments are reliable.
Practical Impact
What quality assurance looks like when you're using Nquiry.
The AI retrieves relevant evidence using hybrid search (meaning-based + keyword)
It assesses each piece of evidence for relevance and material limitations
It produces a structured finding with citations and a confidence level
Three quality checks run independently in the background
Results appear in your quality metrics panel within 30–60 seconds
You see the confidence level, faithfulness score, coverage score, and retrieval quality
You can expand “Evidence Considered” to see exactly what the AI looked at
You review the analysis, check citations, and record your judgment
Everything is logged in the audit trail
At no point does an AI-generated finding enter your report without your explicit agreement.
Limitations
What AI quality checks can and can't do.
What automated checks catch
- Claims not supported by retrieved evidence
- Questions or aspects the analysis fails to address
- Weak evidence retrieval (low relevance scores)
- Structural problems (malformed output, missing fields)
What only you can catch
- Whether the conclusion drawn is actually correct
- Whether evidence was weighed appropriately
- Connections requiring domain expertise to see
- Whether framing is appropriate for your context
This is why the investigator review flow exists. AI checks verify the mechanics. Your expertise verifies the substance.